Elon Musk indicates that the new Tesla FSD model has 5 times the number of parameters. This was done while still being able to run the hardware 3 version of the FSD chip. Hardware 3 has been in the fleet of Tesla cars since March 2019. The simple takeaway is that the AI model being used for FSD is being fundamentally improved by large amounts, which will result in continued improvement of the automated driving of the Tesla cars.
Above is a chart showing how more parameters reduces the errors and improves performance for Meta large language models.
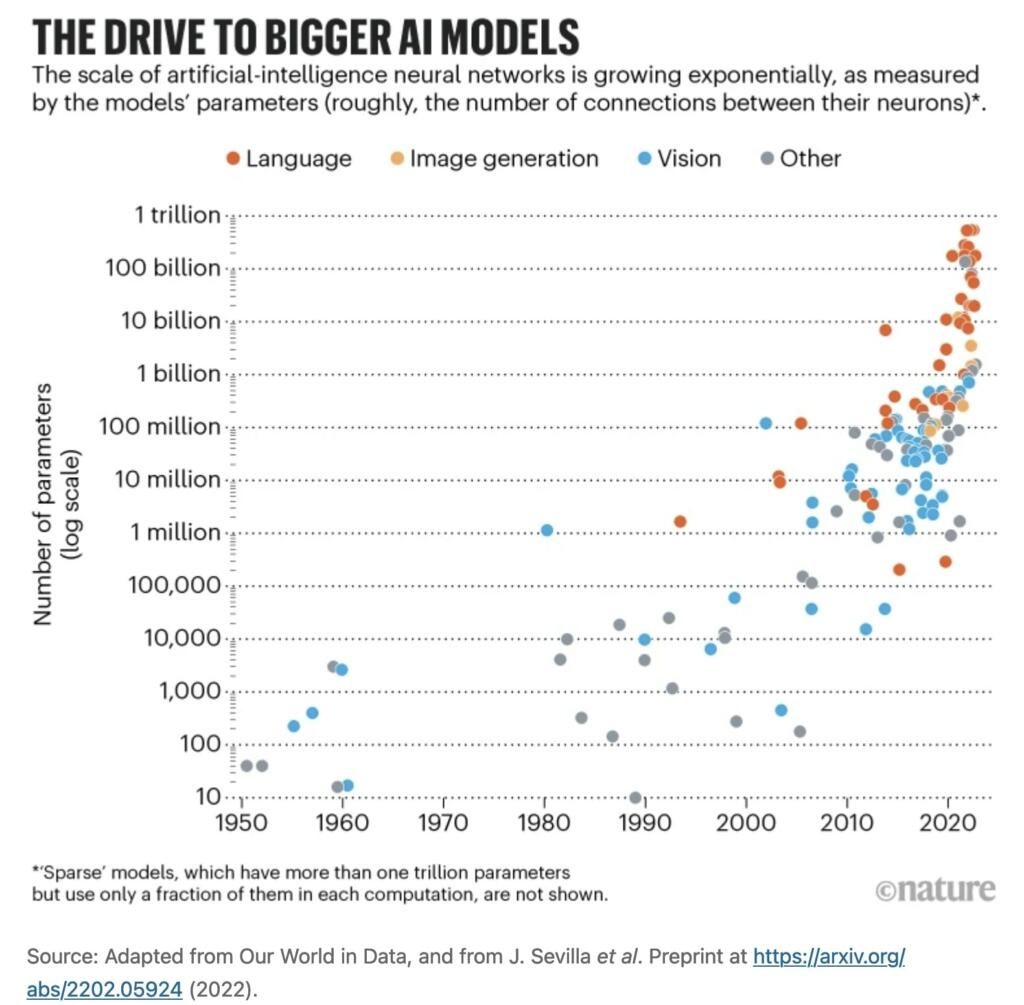
A parameter is like a setting that the AI adjusts to learn from data and make decisions. Each parameter holds a bit of information that the AI uses to understand patterns and generate outputs. The more parameters an AI model has, the more detailed and nuanced its understanding and outputs can be. Think of parameters as dials on a control panel; each one is tweaked during the AI’s training to help it get better at predicting and creating new data that looks like the original training examples.
Two takeaways from Elon’s comments on 12.4.2 (see image)…
1) Training AI is not so straightforward – there’s some trial and error. Tesla is still figuring it out.
2) AI doesn’t learn in a linear way – there can be exponential jumps in its capabilities. We all could be… pic.twitter.com/g8KGqjB0r7
— Cern Basher (@CernBasher) July 1, 2024
Elon says
As the information compression efficiency is held reasonably constant, a higher parameter count is a representation of how well it understands the nuances of reality.
Yeah, so long as the information compression efficiency is held reasonably constant, a higher parameter count is a representation of how well it understands the nuances of reality
— Elon Musk (@elonmusk) July 1, 2024
Cern Basher and Dr Know It All comment on this.
Information Compression Efficiency: This refers to how effectively an AI model can compress or simplify the information it learns without losing important details. It’s about how the model manages to represent complex data with fewer parameters while still performing well. If this efficiency is maintained, it means the model isn’t just getting bigger with more parameters, but it’s also getting better at handling data without unnecessary complexity.
Higher Parameter Count and Understanding Nuances: Elon is suggesting that if an AI model can keep its compression efficiency constant while increasing the number of parameters, then this increase in parameters actually translates into a deeper understanding of the data’s complexities. Essentially, he is saying that more parameters can mean better performance and a more nuanced understanding, but only if the model remains efficient in how it uses those parameters. He is pointing out that more parameters don’t automatically make the model better unless it can effectively use those extra parameters to capture more detailed insights about the data it’s learning from, without getting confused by noise.
Implications for FSD on HW3, HW4 and AI5: Generally speaking, a model with more parameters will require more powerful computational resources to run during the inference phase (when the model is actually being used to make predictions or generate data based on what it has learned). It needs more memory, more power and more energy/cooling. What this means for HW3 is only speculation, but Tesla is developing HW4 and AI5 for a reason.
In other words, a high parameter count is not necessarily the end-all-be-all of deep neural networks. You have to maintain high efficiency in the NN in terms of its “understanding” of the world (for Tesla FSD this would be its world model, or it’s understanding of how photons in…
— DrKnowItAll (@DrKnowItAll16) July 1, 2024
A high parameter count is not necessarily the end-all-be-all of deep neural networks. You have to maintain high efficiency in the NN in terms of its “understanding” of the world (for Tesla FSD this would be its world model, or it’s understanding of how photons in lead to control outputs for steering, braking, acceleration). FSD is in a way like humans: we don’t know everything to drive (what type of rock is that pebble over there? What kind of cloud is that? What sort of slurry was that concrete curb made from?)–we know enough to do it efficiently, which is compression efficiency.
Likewise FSD has to learn to ignore like 99+% of the world and then compress the remaining 1% efficiently to be able to drive properly. This is not at all a trivial matter, which is why FSD often zig-zags toward the solution (ie perfect driving) rather than approaching it linearly.
In general if you have the compute power (ie speed) and memory (GB of RAM) and efficiency remains the same for a larger NN then you get big benefits out of more parameters: it allows a system like FSD to create a more complex, nuanced world model, which means it can drive more like a human–and someday soon, better than any human.

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.